二叉树是我接触的第一个非线性数据结构。在对它进行操作前,如何对其进行构建与遍历很自然地成为了首先要关心的问题。
二叉树的五个性质
二叉树的第i层上至多有\(2^{i - 1}\)个结点
深度为k的二叉树至多有\(2^{k - 1}\)个结点
对任何一棵二叉树T, 其终端结点数为度为2的结点数 + 1
具有n个结点的完全二叉树深度为:\(log_2n + 1\)
满二叉树:每一层结点数都为最大
完全二叉树:每一结点按层的编号都与对应的满二叉树一一对应
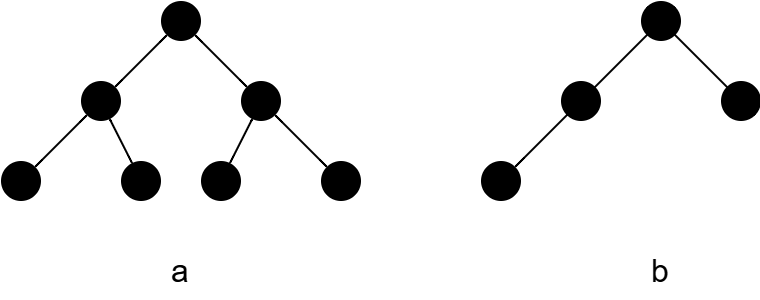
a.满二叉树 b.完全二叉树
对一颗有n个结点的完全二叉树,将其结点按层序编号i,有
i=1,则该结点为根结点,无双亲
2i>n,则结点i无左孩子,否则其左孩子是2i
2i + 1 > n则结点无右孩子,否则其右孩子是2i + 1
二叉树的存储结构
1. 顺序存储结构
将完全二叉树上序号为i的结点存在数组中标号为i - 1的地址中,如非完全二叉树,则空出来的地址留空。此时子结点用性质5即可得到。

上面三个二叉树的存储结构分别为:

(用0表示结点不存在)
可以看出,当二叉树不是完全二叉树时,这种结构非常浪费存储空间。因此仅适合用作完全二叉树的存储。
2. 链式存储结构
二叉树用链表来存储是非常自然的,常见的有二叉链表和三叉链表。
二叉链表
二叉链表的组织形式:

三叉链表
三叉链表在二叉链表的基础上添加了指向父结点的指针,与二叉链表大同小异。
三叉链表的组织形式:

代码实现
typedef struct Node
{
Node *leftChild;
Node *rightChild;
int data;
} *BinTree;
int CreateBinTree(BinTree &tree)
{
tree = new Node{nullptr, nullptr, 0};
if(tree == nullptr)
{
cerr << "Error While Create BinTree!" << endl;
return -1;
}
return 0;
}
int InsertChild(Node *aim, bool left)
{
Node *newNode = new Node{nullptr, nullptr, 0};
if(newNode == nullptr)
{
cerr << "Error While Add Note!" << endl;
return -1;
}
if(left)
{
aim->leftChild = newNode;
}
else
{
aim->rightChild = newNode;
}
return 0;
}
int DeleteChild(Node *aim, bool left)
{
if(aim == nullptr) return -1;
Node *preDel = (left) ? aim->left : aim->right;
if(preDel != nullptr)
{
if(preDel->left != nullptr)
{
DeleteChild(preDel, left);
}
if(preDel->right != nullptr)
{
DeleteChild(preDel, right);
}
delete preDel;
preDel = nullptr;
}
if(left)
{
aim->left = nullptr;
}
else
{
aim->right = nullptr;
}
return 0;
}
int Visit(Bintree T)
{
if(T == nullptr) return -1;
cout << T->data << endl;
return 0;
}二叉树的遍历
要遍历二叉树,可将二叉树分为三个部分,左子树(L)、根(D)、右子树(R),并依次访问每个部分。若规定左子树一定先于右子树访问,则共有三种情况:DLR、LDR、LRD。分别称为前(先)序遍历、中序遍历和后序遍历。
这三种遍历的算法是递归描述的,如下:
前序遍历
算法描述
若二叉树为空,则空操作,否则
- 访问根结点
- 先序遍历左子树
- 先序遍历右子树
算法的递归实现
int DLR(BinTree T)
{
if(T == nullptr) return 0;
if(Visit(T) == -1) return -1;
if(DLR(T->left) == -1) return -1;
if(DLR(T->right) == -1) return -1;
return 0;
}中序遍历
算法描述
若二叉树为空,则空操作,否则
- 中序遍历左子树
- 访问根结点
- 中序遍历右子树
算法的递归实现
int LDR(BinTree T)
{
if(T == nullptr) return 0;
if(LDR(T->left) == -1) return -1;
if(Visit(T) == -1) return -1;
if(LDR(T->right) == -1) return -1;
return 0;
}后序遍历
算法描述
若二叉树为空,则空操作,否则
- 后序遍历左子树
- 后序遍历右子树
- 访问根结点
算法的递归实现
int LRD(BinTree T)
{
if(T == nullptr) return 0;
if(LRD(T->left) == -1) return -1;
if(LRD(T->right) == -1) return -1;
if(Visit(T) == -1) return -1;
return 0;
}三种遍历的非递归实现
原理
由上面的描述可以看出用递归实现三种遍历是非常简洁自然的,然而在大部分情况下递归实现的性能开销大于非递归实现(函数反复调用以及系统堆栈带来的),因此在非常需要考虑性能时可以使用算法的非递归实现(算法的递归几乎都可以转化成非递归实现)。
为了实现非递归遍历,先来看看遍历过程中发生了什么。
在遍历过程中,每个结点有三次访问机会,即指针从父结点指向自身,从左孩子退回,从右孩子退回。这里我们不妨规定没有左/右孩子的结点仍能获得空指针退回的访问机会(即将空指针看做一个无法进入的孩子结点)。

由于我们规定了左子树一定在右子树之前遍历,整个树的遍历顺序就如上图所示(a->b)。我们在每个结点的左侧、下侧和右侧分别设定一个触发点,并将它们在遍历路径中出现的顺序记录下来。
对于左触发点:ABDECFG
对于下触发点:DBEAFCG
对于右触发点:DEBFGCA
可以看出,它们分别是这个二叉树的前序序列、中序序列和后序序列。因此,实现正确的遍历顺序,并在合适的时机访问结点,就可以实现非递归地遍历二叉树。
前序遍历和中序遍历
前序遍历和中序遍历的实现相对后序遍历简单,描述为:
- 向左一路前进,若下一结点为空则退栈,否则将其压入栈中。
- 若指针是左子树退回,则进入右子树。若指针是右子树退回,则表示当前层遍历结束,继续退一层。这也意味着进入右子树时可以将当前结点直接退栈。
- 栈为空时,遍历完成。
int LDR(BinTree T)
{
//定义一个存储遍历信息的栈和一个用来遍历树的指针
stack<Node*> S;
Node *cur = T;
//每访问一个结点就将结点出栈,因此以栈非空作为循环条件
//最后出栈的必是一个叶子结点,因此指针的值在结束时必为nullptr
while(!S.empty() || cur != nullptr)
{
//指针非空时一路向左走并将沿途结点压入栈中
//指针为空则表示走到了当前路径的尽头,将最后入栈的结点出栈并令指针指向该结点的右子树
if(cur != nullptr)
{
S.push(cur);
//cout << cur->data; 前序时在此输出。
cur = cur->left;
}
else
{
cur = S.top();
S.pop();
cout << cur->data; //中序时在此输出。
cur = cur->right;
}
}
return 0;
}总结:一路向左,非空则进。遇空出栈,右子代之。
后序遍历
在前面的代码中我们实际上省略了对指针是由左子树退回还是右子树退回的判断,直接在指针进入右子树时将当前结点出栈。对于前序遍历和中序遍历而言这样做并没有影响,因为它们的访问操作都在指针进入右子树之前。但是对于后序遍历显然是不行的,这里对上述算法进行改进:
- 指针非空时向左前进到底,若指针非空则压入栈中,初始化一个指针保存最近出栈的结点。
- 指针为空时令指针指向栈顶,进行判定,若指针的右子树存在且没有遍历过则进入右子树,否则输出指针所指元素并退栈。同时将指针置零以免将已退栈的元素重新入栈。
- 栈为空时,遍历完成。
int LRD(BinTree T)
{
stack<Node*> S;
Node *cur = T;
//存储最后退栈的元素
Node *lastPop = nullptr;
while(!S.empty() || cur != nullptr)
{
//非空时向左前进到底
if(cur != nullptr)
{
//cout << cur->data; 仍然可用于前序遍历
S.push(cur);
cur = cur->left;
}
else
{
cur = S.top();
//判定当前结点是否存在右子树以及右子树是否遍历过
//此处是否存在的判定是必要的,否则当lastPop非空而当前结点又不存在右子树时,
//将导致指针不断尝试进入不存在的右子树引发死循环
if(cur->right != nullptr && cur->right != lastPop)
{
//cout << cur->data; 中序遍历输出根结点
cur = cur->right;
}
else
{
//右子树不存在或已遍历过,输出根结点并退栈
S.pop();
cout << cour->data;
//if(cur->right == nullptr) cout << cur->data; 中序遍历输出叶子结点
//令lastPop指向最后退栈结点,将cur指针置0以免下一轮循环将已退栈的结点重新入栈
lastPop = cur;
cur = nullptr;
}
}
}
return 0;
}总结:一路向左,非空则进,遇空判定,有右则进,无右则出,不忘置零。
图解后序遍历的非递归算法

精力有限,只好挑一个难度最大的做图解。
通过中序序列+前序/后序序列构建二叉树
原理
前序序列中任一子树以根结点-左子树-右子树的结构排列。
中序序列中任一子树以左子树-根结点-右子树的结构排列。
后序序列中任一子树以左子树-右子树-根结点的结构排列。
根据以上性质,可以得到算法:
- 从前/后序序列中取首/尾元素,确定树的根结点
- 在中序序列中搜索根结点,确定左子树和右子树
- 对左子树和右子树分别重复这个过程,直到不可再分
图解:以前序-中序构建为例

代码实现
前序-中序构建二叉树
//根据前序-中序序列构建二叉树,代码是通过递归实现的
//SI是string::iterator类型,函数的四个参数分别指向
//前序序列p的首元素和尾后元素,中序序列m的首元素和尾后元素
BinTree Pre_Mid_Build(SI p_begin, SI p_end, SI m_begin, SI m_end)
{
//用前序序列的首元素初始化一个仅有根结点的树
Node *boot = new Node{nullptr, nullptr, *p_begin};
//左子树的前序序列首元素地址为当前前序序列的首元素地址+1
//中序序列的首元素地址和当前中序序列相同
auto left_p_begin = p_begin + 1;
//左子树中序序列的尾后地址为根结点在当前中序序列中出现的位置
//搜索当前中序序列求出,并求出左子树的长度
auto left_m_end = m_begin;
int num = 0;
while(*left_m_end != *p_begin)
{
++left_m_end;
++num;
}
//利用左子树的长度求出左子树前序序列的尾后迭代器
auto left_p_end = left_p_begin + num;
//若左子树存在,递归构建左子树
if(m_begin != left_m_end)
{
boot->left = Pre_Mid_Build(left_p_begin, left_p_end, m_begin, left_m_end);
}
//右子树的迭代器比较方便取得
auto right_p_begin = left_p_end;
auto right_m_begin = left_m_end + 1;
//若右子树存在,递归构建右子树
if(right_m_begin != m_end)
{
boot->right = Pre_Mid_Build(right_p_begin, p_end, right_m_begin, m_end);
}
return boot;
}中序-后序构建二叉树
//代码与前序-中序大同小异,不再写注释
BinTree Post_Mid_Build (SI p_begin, SI p_end, SI m_begin, SI m_end)
{
Node *boot = new Node{nullptr, nullptr, *(p_end - 1)};
auto left_m_end = m_begin;
int num = 0;
while(*left_m_end != *(p_end - 1))
{
++left_m_end;
++num;
}
auto left_p_end = p_begin + num;
if(m_begin != left_m_end)
{
boot->left = Post_Mid_Build (p_begin, left_p_end, m_begin, left_m_end);
}
auto right_p_begin = left_p_end;
auto right_p_end = p_end - 1;
auto right_m_begin = left_m_end + 1;
if(right_m_begin != m_end)
{
boot->right = Post_Mid_Build (right_p_begin, right_p_end, right_m_begin, m_end);
}
return boot;
}计算一对先序序列和后序序列可能表示的二叉树个数
原理
前序序列中任一子树以根结点-左子树-右子树的结构排列。
后序序列中任一子树以左子树-右子树-根结点的结构排列。
可能混淆的情况有:根(左/右)+(左/右)根。
可以知道,前序序列与后序序列中任何有两个子树的树都是确定的。而每一对仅一个子树的树将有两种可能结构。
因此只要求出序列对中有多少对无法确定的子树即可,很容易发现这样的树对以AB & BA的方式存在。只要搜索两个序列即可。
代码
//因为要用到位运算, 使用无符号类型
using UL = unsigned long;
int main()
{
string pre, post;
cin >> pre >> post;
//搜索并计数
UL sum = 0;
for(UL i = 0; i < pre.length() - 1; ++i)
{
for(UL j = 1; j < post.length(); ++j)
{
if(pre[i] == post[j] && pre[i + 1] == post[j - 1])
{
++sum;
}
}
}
UL base = 1;
//位运算计算2的次幂方便且快速,注意括号
cout << (base<<sum) << endl;
return 0;
}